

Поиск оптимального f пo ячеистым данным
Глава 1 Глава 2
Теперь мы рассмотрим поиск оптимального f и его побочных продуктов по ячеистым данным. Этот подход также является гибридом параметрического и эмпирического метода и аналогичен процессу поиска оптимального f по различным сценариям; только на этот раз мы будем использовать среднюю точку ячейки. Для каждой ячейки у нас будет ассоциированная вероятность, рассчитанная как общее число элементов (сделок) в этой ячейке, деленное на общее число элементов (сделок) во всех ячейках. Для каждой ячейки у нас будет ассоциированный результат, рассчитанный по центральной точке ячейки.
Например, у нас есть 3 ячейки и 10 сделок. Первую ячейку мы определим для P&L от -1000 долларов до -100 долларов. В этой ячейке будет два элемента. Следующая ячейка предназначена для сделок от -100 до 100 долларов, она вмещает 5 сделок.
Наконец, в третью ячейку попадут 3 сделки, которые имеют P&L от 100 до 1000 долларов.

Теперь нам нужно решить уравнение (4.16), где каждая ячейка представляет отдельный сценарий. Таким образом, для случая с 3 ячейками оптимальное f составляет 0,2, или 1 контракт на каждые 2750 долларов на счете (наш проигрыш наихудшего случая будет средней точкой первой ячейки, или (-$1000 + -$100) / /2 =-$550). Этот метод можно использовать в реальной торговле, хотя он и недостаточно точен, поскольку допускает, что наибольший проигрыш находится в середине наихудшей ячейки, а это не совсем верно. Часто полезно иметь одну лишнюю ячейку, чтобы включить проигрыш наихудшего случая. Допустим, как и в примере с 3 ячейками, у нас была сделка с проигрышем в 1000 долларов. Такая сделка попадает в ячейку -1000 до -100 долларов и поэтому будет записана как 550 долларов (средняя точка ячейки), но мы можем разместить в ячейки те же данные следующим образом:
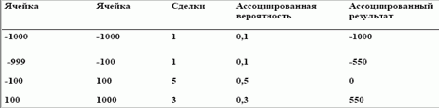
Теперь оптимальное f составляет 0,04, или 1 контракт на каждые 25 000 долларов на счете. Вы видите, насколько приблизителен этот метод? Поэтому, хотя этот метод даст нам оптимальное f для ячеистых данных, надо понимать, что потеря информации при размещении данных в ячейки может сделать результаты настолько неточными, что они станут бесполезными. Если бы у нас было больше точек данных и больше ячеек, метод был бы намного точнее. Фактически, если бы у нас было бесконечное количество данных и бесконечное число ячеек, метод был бы абсолютно точным (если бы данные в каждой из ячеек были равны средним точкам соответствующих ячеек, то этот метод также был бы точным). Другой недостаток предлагаемого метода заключается в том, что среднее значение ячейки не обязательно расположено в центре ячейки. В реальности среднее значение элементов в ячейке будет ближе к моде всего распределения, чем к средней точке ячейки. Следовательно, полученная дисперсия будет больше, чем есть на самом деле. Существуют способы корректировки, но и они могут быть неточными.
Проблему можно было бы преодолеть, и результаты были бы точными при бесконечном количестве элементов (сделок) и бесконечном количестве ячеек. Если у вас есть достаточно большое количество сделок и достаточно большое количество ячеек, вы можете использовать этот метод с большей уверенностью.
Вы также можете провести тесты «что если», изменяя число элементов в различных ячейках, чтобы получить более точное приближение.