Глава 1Глава 2
Чем ниже значение D, тем больше похожи два распределения. Мы можем преобразовать значение D в уровень значимости с помощью следующей формулы:
где SIG = уровень значимости для данного D и N;
D = статистика К-С;
N = количество сделок, по которым определена статистика К-С;
% = оператор, означающий остаток после деления. Здесь J%2 дает остаток после
деления J на 2;
ЕХР() = экспоненциальная функция.
Нет необходимости суммировать значения J от 1 до бесконечности. Уравнение сходится (обычно очень быстро) к определенному значению. После того как предел достигнут (согласно допуску, установленному пользователем), нет необходимости продолжать суммирование значений.
Рассмотрим уравнение (4.01) на примере. Допустим, у нас есть 100 сделок, а значение статистики К-С равно 0,04:
Прибавив -0,5560746 к нашей текущей сумме 1,452298, мы получим новую текущую сумму 0,8962234. Затем снова увеличим J на 1, теперь оно будет равно 3, и решим уравнение. Получившееся значение прибавим к текущей сумме 0,8962234.
Следует поступать таким образом и дальше, пока текущая сумма в пределах допуска не перестанет изменяться. В нашем примере предельное значение будет равно 0,997. Этот ответ означает, что при 100 сделках и значении статистики К-С 0,04 мы можем быть уверены на 99,7%, что фактическое распределение генерировано функцией теоретического распределения. Другими словами, мы можем быть на 99,7% уверены, что функция теоретического распределения представляет фактическое распределение. В данном случае это очень хороший уровень значимости.


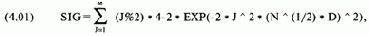 где SIG = уровень значимости для данного D и N;
D = статистика К-С;
N = количество сделок, по которым определена статистика К-С;
где SIG = уровень значимости для данного D и N;
D = статистика К-С;
N = количество сделок, по которым определена статистика К-С;